
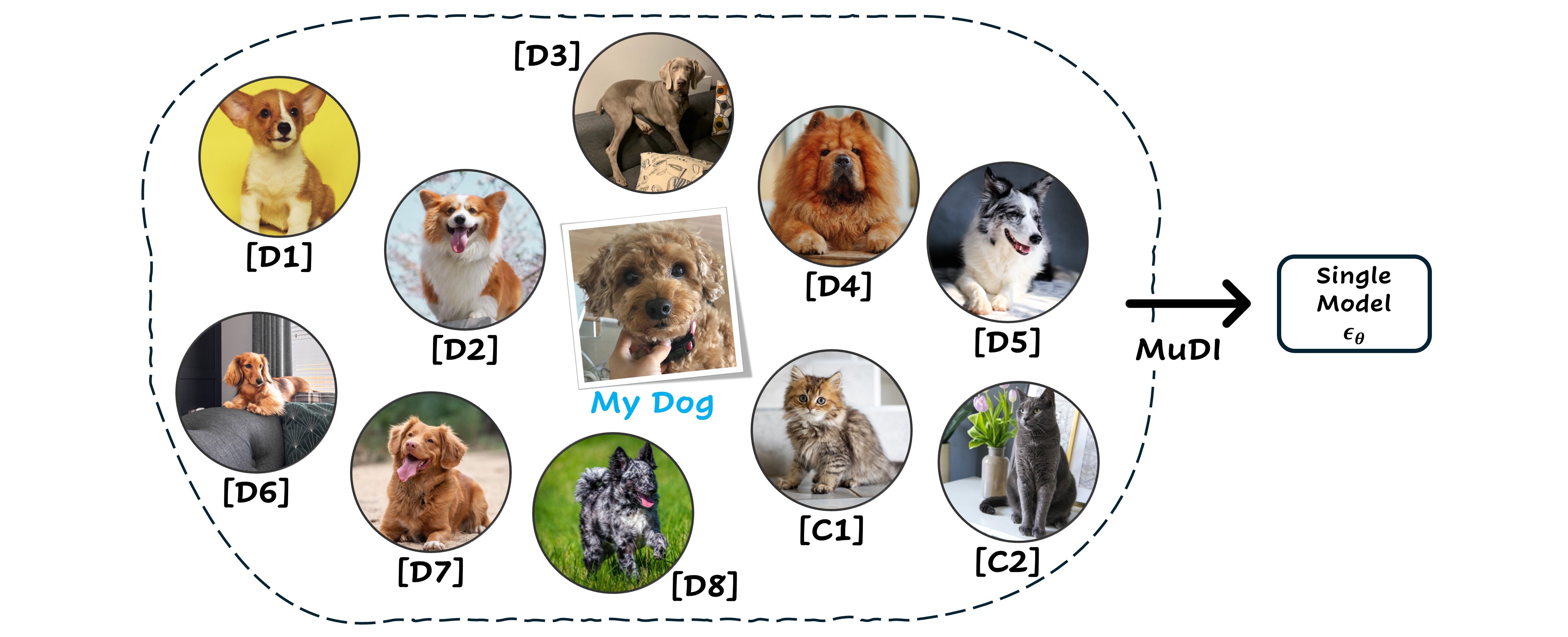




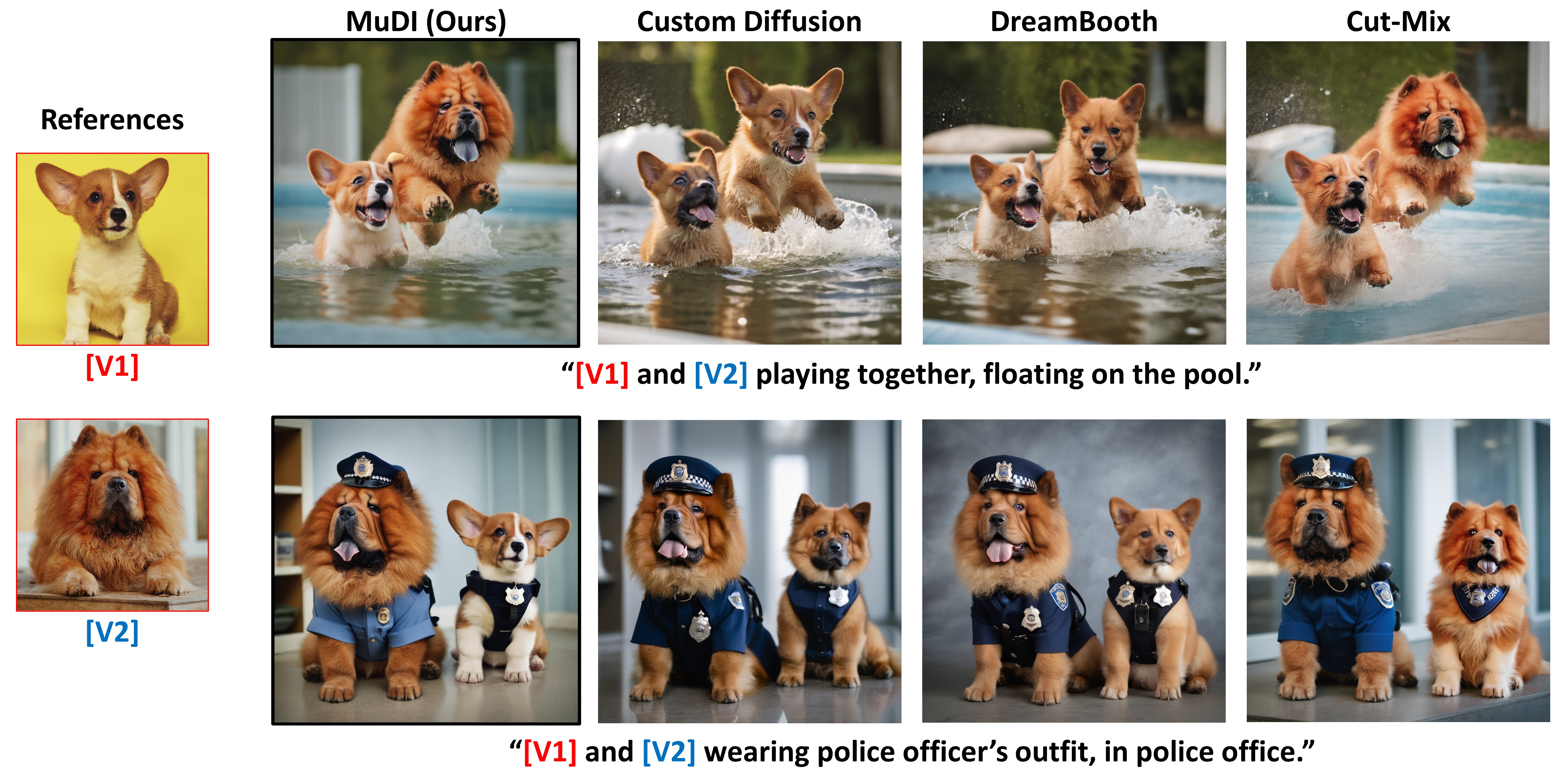
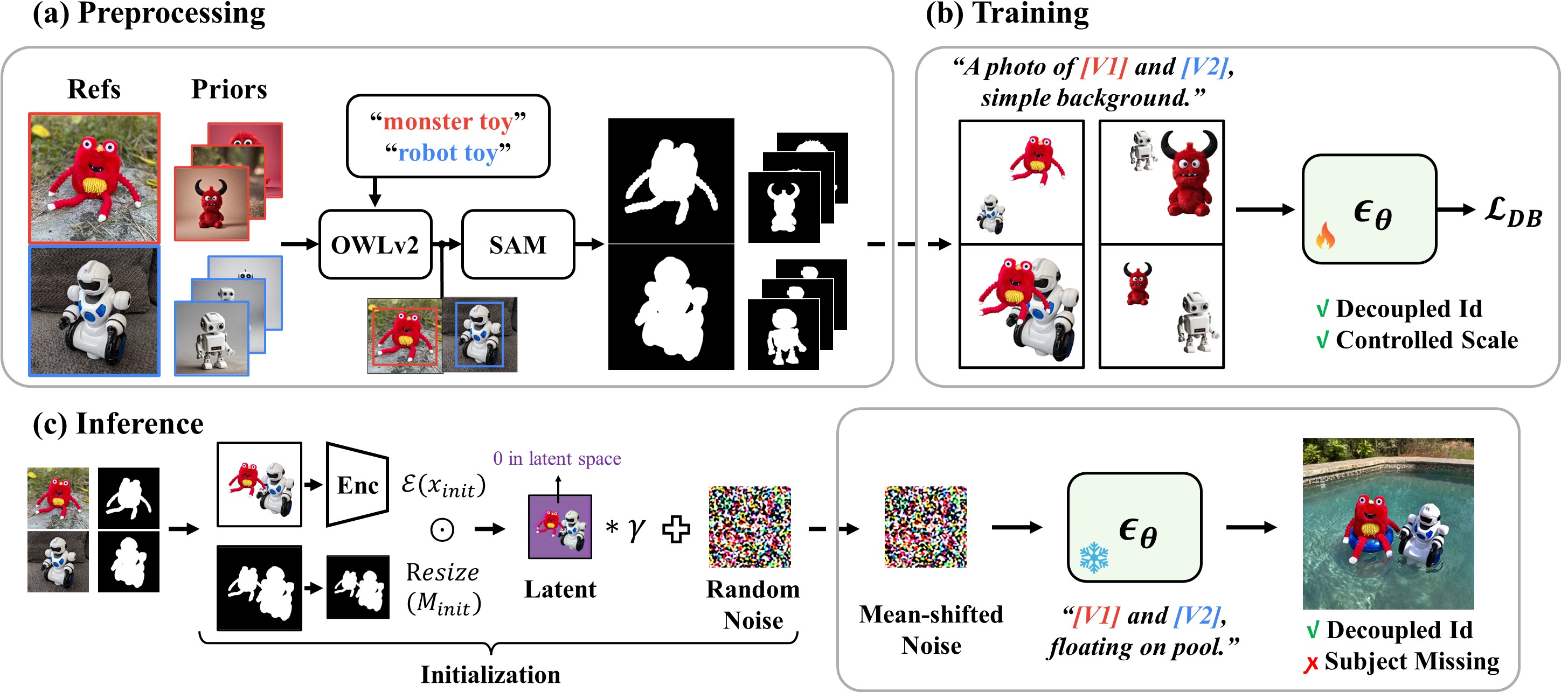
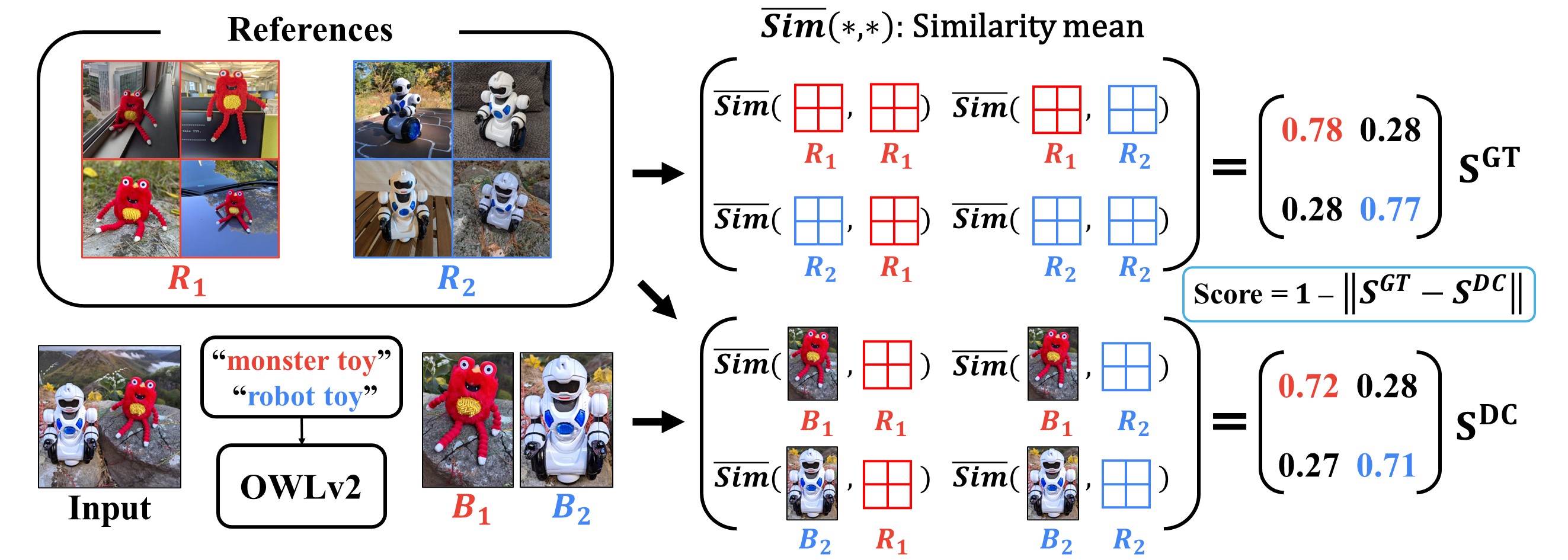
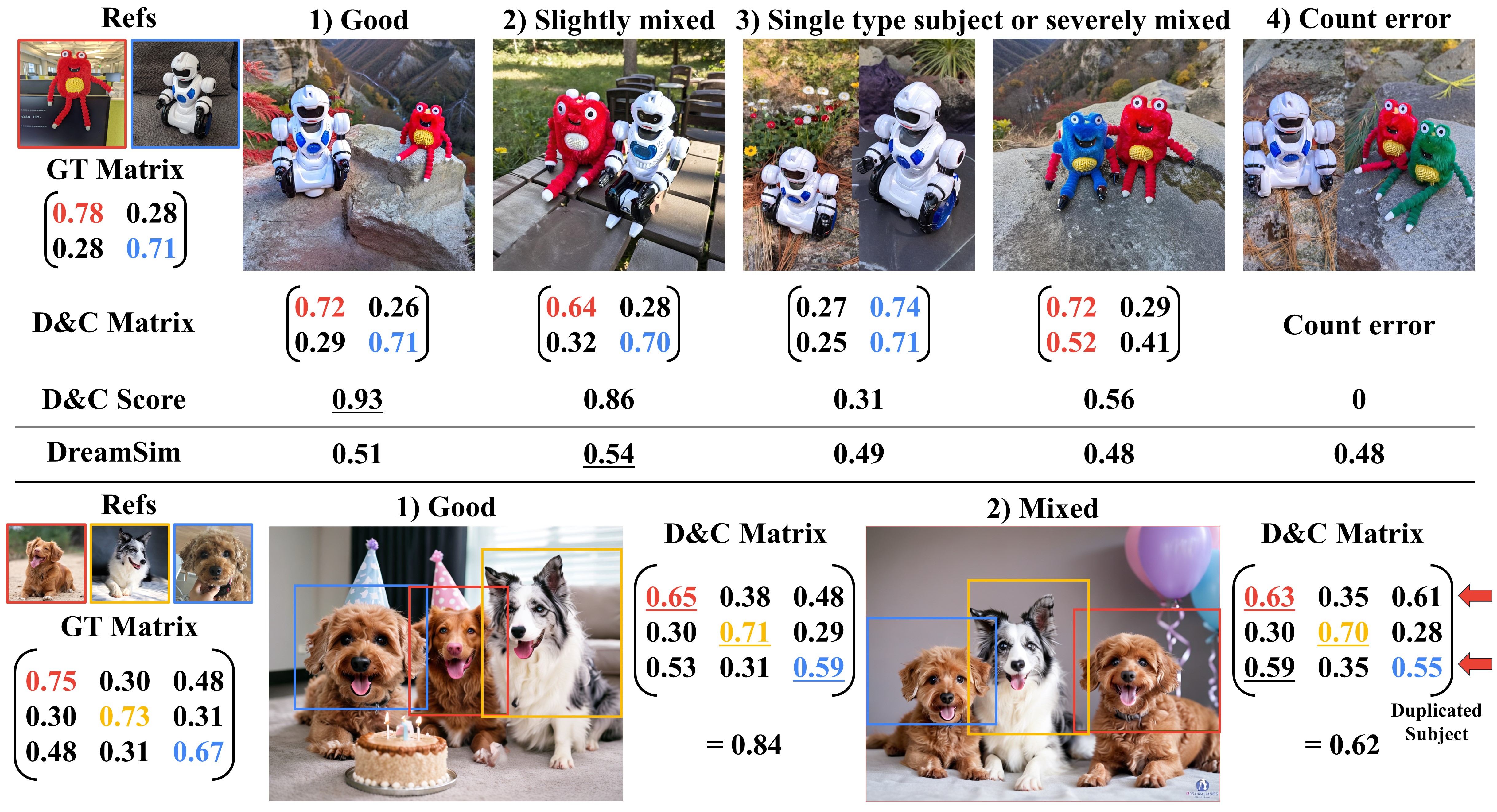
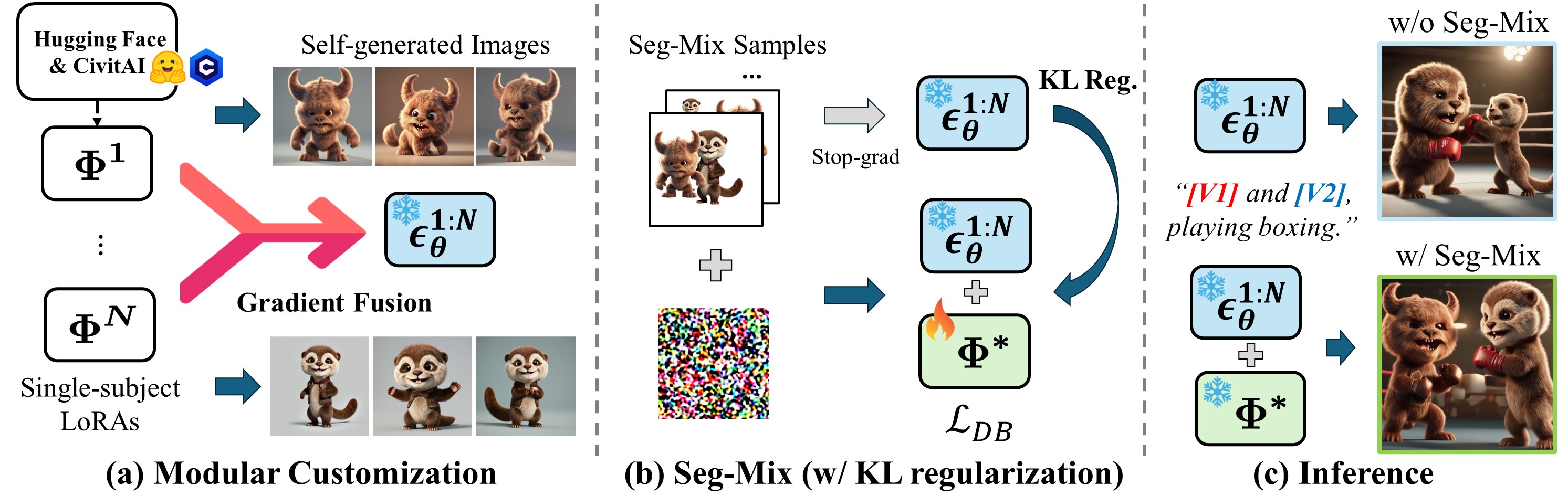
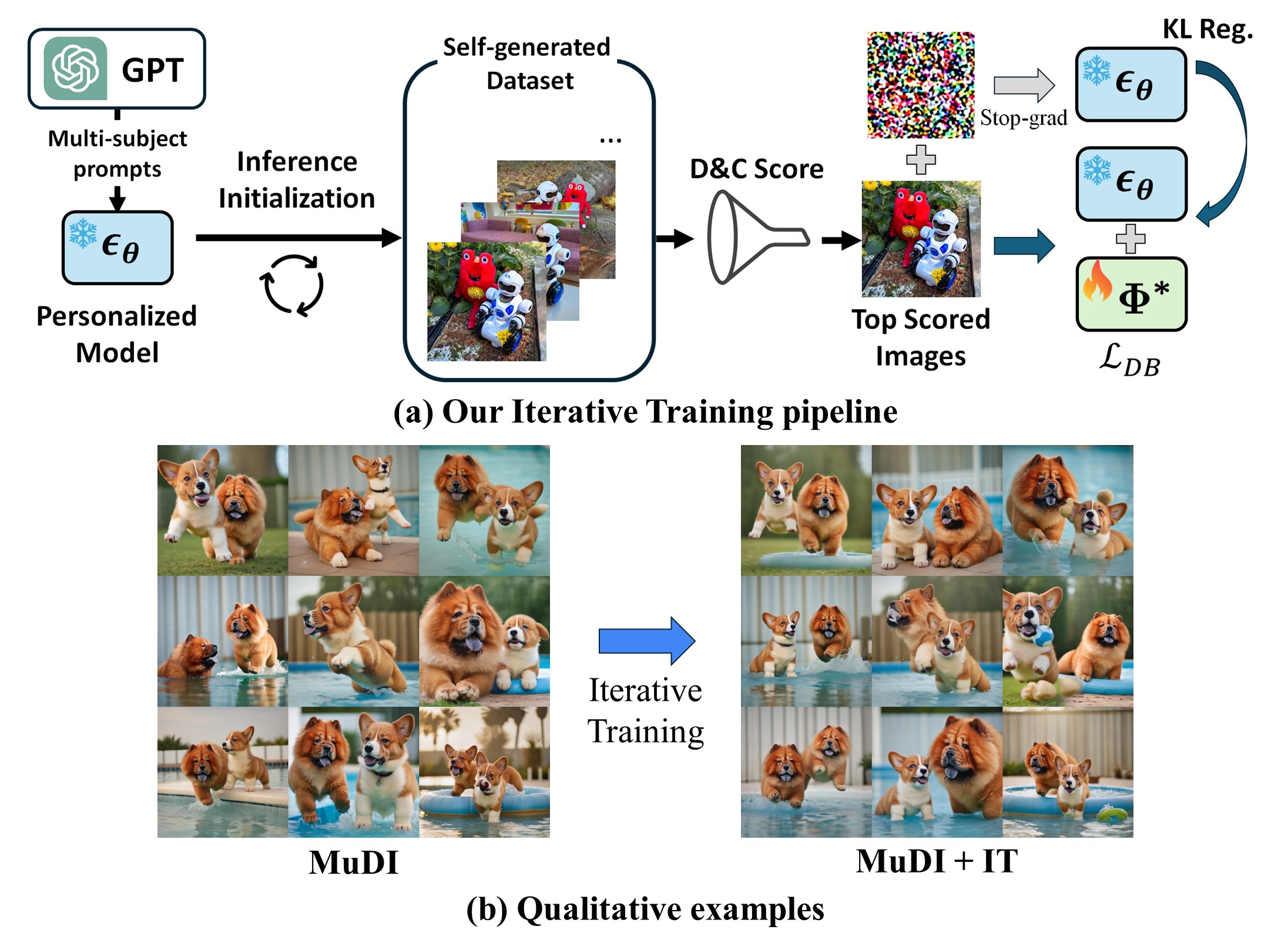
Text-to-image diffusion models have shown remarkable success in generating personalized subjects based on a few reference images. However, current methods often fail when generating multiple subjects simultaneously, resulting in mixed identities with combined attributes from different subjects. In this work, we present MuDI, a novel framework that enables multi-subject personalization by effectively decoupling identities from multiple subjects. Our main idea is to utilize segmented subjects generated by a foundation model for segmentation (Segment Anything) for both training and inference, as a form of data augmentation for training and initialization for the generation process. Moreover, we further introduce a new metric to better evaluate the performance of our method on multi- subject personalization. Experimental results show that our MuDI can produce high-quality personalized images without identity mixing, even for highly similar subjects. Specifically, in human evaluation, MuDI obtains twice the success rate for personalizing multiple subjects without identity mixing over existing baselines and is preferred over 70% against the strongest baseline.








@misc{jang2024identity,
title={Identity Decoupling for Multi-Subject Personalization of Text-to-Image Models},
author={Sangwon Jang and Jaehyeong Jo and Kimin Lee and Sung Ju Hwang},
year={2024},
eprint={2404.04243},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@inproceedings{
jang2024identity,
title={Identity Decoupling for Multi-Subject Personalization of Text-to-Image Models},
author={Sangwon Jang and Jaehyeong Jo and Kimin Lee and Sung Ju Hwang},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=tEEpVPDaRf}
}